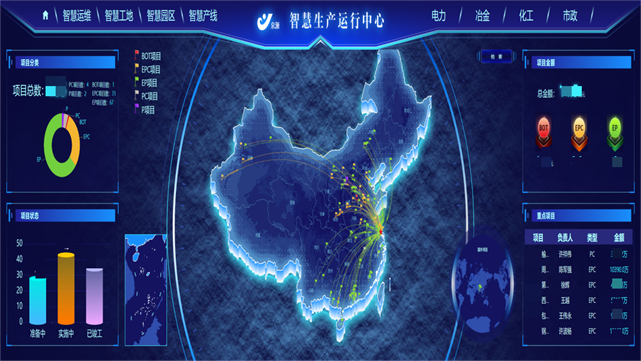
业务连续性规划(BCP)严重依赖于对系统依赖关系和风险点的准确认知。智慧运维平台中动态生成的应用拓扑图、梳理出的关键业务链路、以及历史故障影响范围分析,为制定准确的BCP提供了较真实的数据基础。平台可以模拟不同灾难场景(如单个AZ故障、数据库宕机)对业务的影响,并验证容灾切换方案的有效性。这使得BCP从一份静态的文档,变成了一个基于实时系统状态、可数据化验证的动态管理过程。没有一个平台能解决所有问题,因此智慧运维平台的生态与集成能力至关重要。良好的平台应提供丰富的API、SDK和插件机制,能够轻松与现有的ITSM、CMDB、自动化工具、通信平台(如Slack、钉钉)以及云服务商的原生监控服务集成。通过构建一个开放的生态系统,智慧运维平台可以成为运维工具链的“指挥中心”,聚合各方数据与能力,而不必替代所有工具,从而以更灵活、更低成本的方式创造价值。智慧运维平台助力能源企业实现从传统运维到智慧运维的转型。吉林智慧运维平台联系电话
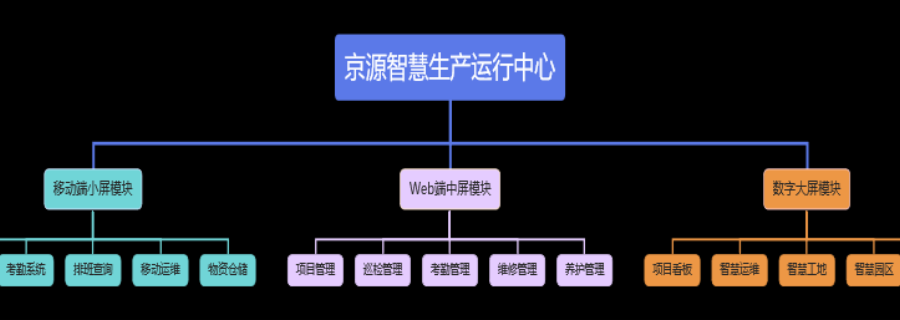
企业在智慧运维平台建设上,面临自建(Build)与外购(Buy)的抉择。自建平台(基于开源组件如Elastic Stack、Prometheus、SkyWalking进行集成开发)具有高度的灵活性和可控性,能够深度定制以适应独特需求,但对团队技术实力、时间和持续投入要求极高。外购商业产品则能快速上线,享受厂商的持续研发和专业服务,但可能在成本、数据权利和与现有流程的集成度上存在挑战。企业需综合评估自身的技术能力、业务需求复杂度、预算和时间窗口,做出比较符合长期利益的战略选择。贵州新能源智慧运维平台该平台采用微服务架构,方便用户根据需求进行功能模块的扩展。
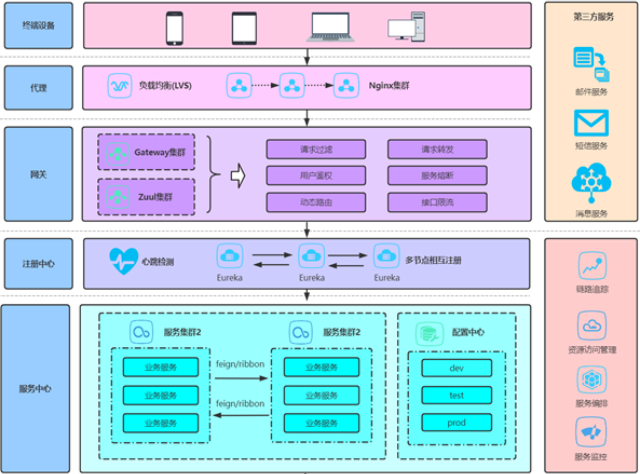
告警疲劳是运维团队的顽疾。智慧运维平台通过AI实现告警的智能降噪、压缩和路由。它能将同一根因产生的大量衍生告警合并为一条主事件;能根据告警的历史处理记录和学习运维人员的反馈,动态调整告警的优先级;还能根据值班表、技能标签和事件类型,将告警准确推送给较合适的处理人员,避免无关信息的干扰。这极大地提升了告警的有效性和可操作性,让每一次告警都成为有价值的行动指令,而非令人麻木的噪音。智慧运维平台的自动化能力不应是零散的脚本,而应是端到端的流程编排。例如,对于一个“磁盘空间告警”,自动化流程可以是:首先确认告警有效性 -> 自动登录服务器清理日志文件 -> 若清理后空间仍不足,则自动扩容磁盘 -> 更新CMDB配置信息 -> 较终关闭相关告警工单。平台通过图形化的流程设计器,将多个原子操作串联成一个完整的、可复用的自动化剧本,实现了复杂运维场景的“一键式”处置,明显提升了运营效率。
智慧运维平台引入知识图谱技术,将运维手册、故障处理案例、专业人士经验等非结构化数据转化为结构化知识网络。通过实体识别与关系抽取,构建设备、故障、解决方案之间的关联模型,当系统检测到新的故障特征时,能够自动匹配相似历史案例并推送比较好解决方案;同时支持运维人员实时补充知识节点,形成 “故障处理 - 经验沉淀 - 智能推荐” 的闭环,加速新手运维人员的成长,降低对一些专业人士的依赖,实现运维知识的规模化复用。针对云原生架构的普及,智慧运维平台深度适配 Kubernetes、Docker 等容器技术,提供从容器编排到应用治理的全生命周期运维支持。平台可自动发现容器集群中的节点、Pod、服务等资源,实时监控容器 CPU、内存、网络等指标,并支持容器日志的集中采集与分析;通过与 CI/CD 工具链集成,实现应用的自动化部署、滚动更新与回滚操作,确保云原生应用的稳定运行;同时提供多租户隔离能力,满足企业在混合云、多云环境下的资源统一管理需求。智慧运维平台具备报表生成功能,可自动输出多维度运维分析报告。
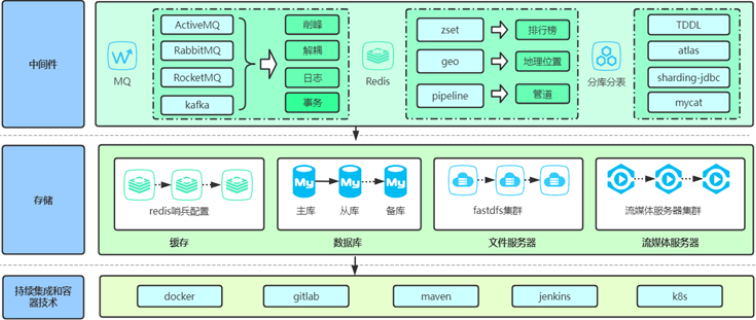
云原生架构(容器、Kubernetes、微服务、服务网格)的弹性和敏捷性,也带来了前所未有的动态性和复杂性,其运维必须依赖智慧运维平台。两者协同共生:智慧运维平台需要深度集成Kubernetes,实现对Pod、Service、Node等资源的自动发现、指标采集和拓扑构建;同时,平台的自愈与弹性策略可以直接通过Kubernetes的HPA、VPA等机制生效。服务网格(如Istio)产生的细粒度遥测数据,更是为微服务级别的可观测性提供了黄金标准。可以说,云原生技术催生了对智慧运维的迫切需求,而智慧运维则保障了云原生架构的稳定、高效运行。园区智慧运维平台支持设备故障的自动报警,提升运维响应的及时性。广西智慧运维平台收费
借助该平台,制造企业可实现设备维护计划的智能生成,提升维护工作效率。吉林智慧运维平台联系电话
可观测性(Observability)是智慧运维的基石,它超越了传统的监控概念,强调从系统外部输出(如日志、指标、追踪)中,能够理解和推断系统内部状态的能力。一个具备高度可观测性的平台,能够让我们不仅知道系统“出了什么问题”,更能理解“为什么会出问题”。它通过整合日志(Logging)记录离散事件、指标(Metrics)反映聚合状态、链路追踪(Tracing)描绘请求全景,构建了理解复杂分布式系统的三维数据模型。没有完善的可观测性数据基础,后续的AI分析与自动化就如同无源之水,智慧运维也就无从谈起。吉林智慧运维平台联系电话
在网络领域,智慧运维平台实现了网络性能管理与诊断(NPMD)的深化。它通过NetFlow/sFlow...
【详情】智慧运维平台强化了应急响应与灾难恢复能力,通过构建全场景应急处置体系,实现故障快速响应与业务快速恢复...
【详情】智慧运维平台的价值需要被有效地传递给内部客户(如业务部门)和外部客户。平台可以生成面向不同角色的价值...
【详情】日志中蕴含着系统行为的较详细记录,但其非结构化的特性使得分析异常困难。智慧运维平台的日志智能分析功能...
【详情】为了应对业务的快速变化,智慧运维平台需要具备足够的灵活性,允许运维人员快速定制监控视图、分析场景和自...
【详情】在网络领域,智慧运维平台实现了网络性能管理与诊断(NPMD)的深化。它通过NetFlow/sFlow...
【详情】传统运维模式高度依赖人工经验与阈值告警,通常在故障发生并对业务造成影响后,团队才被动介入,整个过程耗...
【详情】智慧运维平台的深入应用,必然催生运维组织架构与文化的协同演进。传统的运维团队中,网络、系统、数据库、...
【详情】业务连续性规划(BCP)严重依赖于对系统依赖关系和风险点的准确认知。智慧运维平台中动态生成的应用拓扑...
【详情】全链路监控是智慧运维平台的主要功能之一,通过在应用系统、网络设备、数据库等关键节点部署采集探针,实现...
【详情】自动化是智慧运维价值闭环的“然后一公里”。当平台通过分析诊断出问题根因并形成解决方案后,需要有能力自...
【详情】