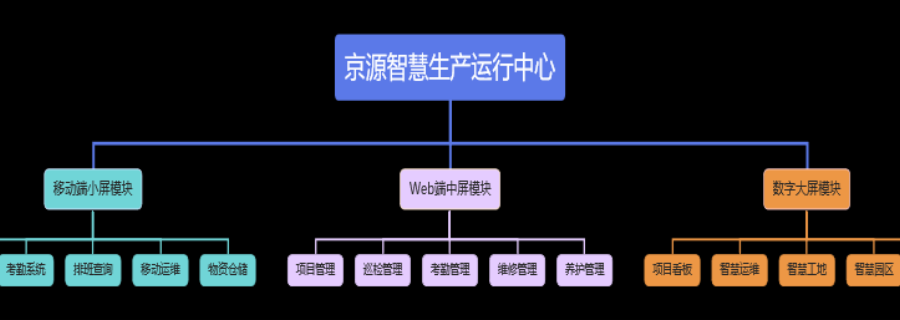
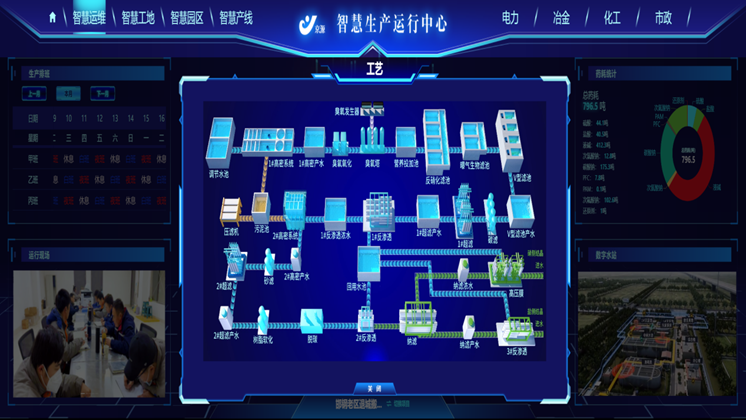
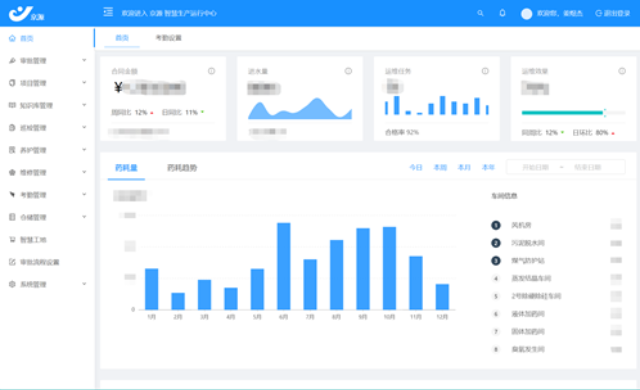
智慧运维平台引入知识图谱技术,将运维手册、故障处理案例、专业人士经验等非结构化数据转化为结构化知识网络。通过实体识别与关系抽取,构建设备、故障、解决方案之间的关联模型,当系统检测到新的故障特征时,能够自动匹配相似历史案例并推送比较好解决方案;同时支持运维人员实时补充知识节点,形成 “故障处理 - 经验沉淀 - 智能推荐” 的闭环,加速新手运维人员的成长,降低对一些专业人士的依赖,实现运维知识的规模化复用。针对云原生架构的普及,智慧运维平台深度适配 Kubernetes、Docker 等容器技术,提供从容器编排到应用治理的全生命周期运维支持。平台可自动发现容器集群中的节点、Pod、服务等资源,实时监控容器 CPU、内存、网络等指标,并支持容器日志的集中采集与分析;通过与 CI/CD 工具链集成,实现应用的自动化部署、滚动更新与回滚操作,确保云原生应用的稳定运行;同时提供多租户隔离能力,满足企业在混合云、多云环境下的资源统一管理需求。针对水电站设备,智慧运维平台可实现运维任务的智能调度。实时监测智慧运维平台价位
为了应对业务的快速变化,智慧运维平台需要具备足够的灵活性,允许运维人员快速定制监控视图、分析场景和自动化流程,而无需等待开发团队的支持。低代码/无代码(LCNC)能力在此背景下显得至关重要。通过图形化拖拽、表单配置和规则引擎,业务运维人员可以自主搭建监控大屏、定义复杂的告警规则、编排自动化处理流程。这极大地降低了平台的使用门槛,加速了运维响应的速度,并使得平台能够更好地适配不同业务线的独特需求,真正成为一个由运维人员主导、随需而变的敏捷工具。

智慧运维平台为数据中心提供了精细化能效管理方案,通过部署温湿度传感器、PDU 功率监测设备等物联网终端,实时采集机房环境与设备能耗数据。平台基于 AI 算法分析能耗与业务负载的关联关系,生成动态节能策略,例如根据服务器利用率自动调节空调送风温度、关闭闲置设备电源;同时通过可视化看板展示 PUE 值、机柜能耗分布等关键指标,帮助运维人员识别能效优化空间,实现数据中心绿色低碳运行,降低运营成本。在工业领域,智慧运维平台实现了从 “被动维修” 到 “预测性维护” 的转型。平台通过采集工业设备的振动、温度、压力等运行数据,结合机器学习算法建立设备健康度评估模型,能够提前识别轴承磨损、电机故障等潜在问题,并生成维护建议与时间窗口;通过与 PLC、SCADA 等工业控制系统联动,可实现设备故障的远程诊断与一键修复,减少生产线停机时间;同时支持设备全生命周期数据追溯,为设备采购、维保计划制定提供数据支撑,提升工业生产的连续性与稳定性。
智慧运维平台使得运维管理可以从粗放式的“设备可用”升级为精细化的“服务等级目标(SLO)”管理。平台能够基于用户体验数据,自动计算关键业务服务的SLO(如“99.9%的请求响应时间小于200ms”),并实时监控其达成情况。通过“错误预算”的概念,将SLO的消耗情况可视化,为团队的发布节奏和风险决策提供客观依据。当错误预算即将耗尽时,平台会发出预警,促使团队将重心从新功能开发转移到稳定性建设上,实现了业务风险与创新速度的科学平衡。该平台融合数字孪生技术,构建设备的虚拟模型,辅助运维决策制定。
作为一个复杂系统,智慧运维平台自身也必须具备高度的可观测性。平台需要监控其数据采集管道的健康度、数据处理的延迟、AI模型的准确率、API的调用性能等。当平台自身出现数据断流、分析延迟或错误时,应能自我感知、自我告警。确保平台自身的稳定、可靠是其为业务系统提供可信服务的前提,这也是“Eating your own dog food”理念在运维领域的体现。在DevOps文化中,智慧运维平台扮演着“反馈中枢”的角色。它将生产环境的真实运行数据(如性能指标、错误日志、用户反馈)持续、透明地反馈给开发团队。这些数据被集成在CI/CD流水线中,成为定义“Done”的标准之一(不仅功能完成,还需满足性能基线)。这种基于数据的快速反馈闭环,驱动开发人员编写更健壮、更易于监控的代码,促进了开发与运维的深度协作,是构建高质量、高韧性软件系统的关键。制造企业部署智慧运维平台后,可提升设备运维团队的响应速度。实时监测智慧运维平台价位
智慧运维平台能对写字楼的能耗数据进行分析,助力建筑节能降耗。实时监测智慧运维平台价位
智慧运维平台能够自动将处理过的故障、根因分析报告、解决方案和应急预案,沉淀为结构化的运维知识库。更重要的是,利用自然语言处理和知识图谱技术,平台可以使这个知识库“智能化”。当新的故障发生时,平台能自动从知识库中匹配相似的历史案例和解决方案,推送给运维人员参考。新问题的解决过程又能反哺知识库,形成一个持续学习和进化的正循环。这有效解决了资历深厚运维人员经验难以传承、知识孤岛化的难题。变更是系统稳定性的比较大威胁之一。智慧运维平台能够对应用发布、配置修改等变更行为进行智能风险评估。平台通过分析历史变更数据,建立变更与系统稳定性之间的关联模型。当一次新的变更即将执行时,平台可以预测其可能导致的风险等级,并给出预警。例如,如果某个微服务的历史发布失败率较高,或本次变更涉及的代码模块是主要且脆弱的部分,平台会建议在低峰期执行或要求增加更充分的测试。这为变更管理提供了数据驱动的决策支持。实时监测智慧运维平台价位
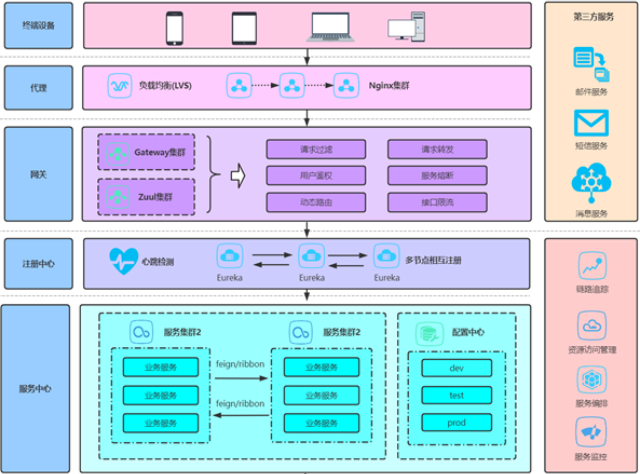
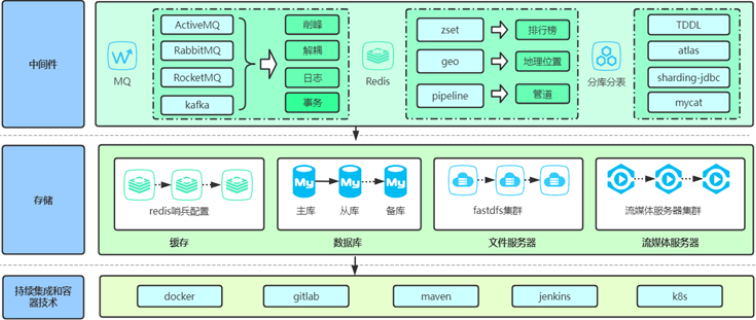
智慧运维平台的根基在于其强大的数据融合与处理能力。它如同运维的“数字感官”,通过各类Agent、AP...
【详情】智慧运维平台引入知识图谱技术,将运维手册、故障处理案例、专业人士经验等非结构化数据转化为结构化知识网...
【详情】在智慧运维的体系中,数据是毋庸置疑的新“石油”。平台通过构建统一的数据湖或数据中台,打破了以往监控、...
【详情】在现代应用性能管理(APM)中,智慧运维平台通过嵌入应用的探针,采集从用户端到服务端全链路的深度数据...
【详情】针对中小微企业 IT 资源有限、运维人员不足的痛点,智慧运维平台推出了轻量化版本解决方案。该版本简化...
【详情】作为一个复杂系统,智慧运维平台自身也必须具备高度的可观测性。平台需要监控其数据采集管道的健康度、数据...
【详情】智慧运维平台提供了丰富的可视化展示功能,通过拖拽式编辑器可自定义运维大屏、业务看板等展示页面。平台支...
【详情】传统运维模式高度依赖人工经验与阈值告警,通常在故障发生并对业务造成影响后,团队才被动介入,整个过程耗...
【详情】智慧运维平台的价值需要被有效地传递给内部客户(如业务部门)和外部客户。平台可以生成面向不同角色的价值...
【详情】在现代应用性能管理(APM)中,智慧运维平台通过嵌入应用的探针,采集从用户端到服务端全链路的深度数据...
【详情】为了应对业务的快速变化,智慧运维平台需要具备足够的灵活性,允许运维人员快速定制监控视图、分析场景和自...
【详情】在网络领域,智慧运维平台实现了网络性能管理与诊断(NPMD)的深化。它通过NetFlow/sFlow...
【详情】